在本页面,我们将深入讲解如何使用Python的requests库下载大文件,并在下载过程中实时显示进度。这不仅能提高用户体验,还能帮助开发者监控下载状态。
示例代码
import requests
def download_file(url,save_file,chunk_size=8192):
try:
response = requests.get(url, stream=True)
response.raise_for_status()
total_size = int(response.headers.get('content-length', 0))
downloaded_size = 0
with open(save_file, 'wb') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
if chunk:
f.write(chunk)
downloaded_size += len(chunk)
if total_size == 0:
done = 0
else:
done = int(50 * downloaded_size / total_size)
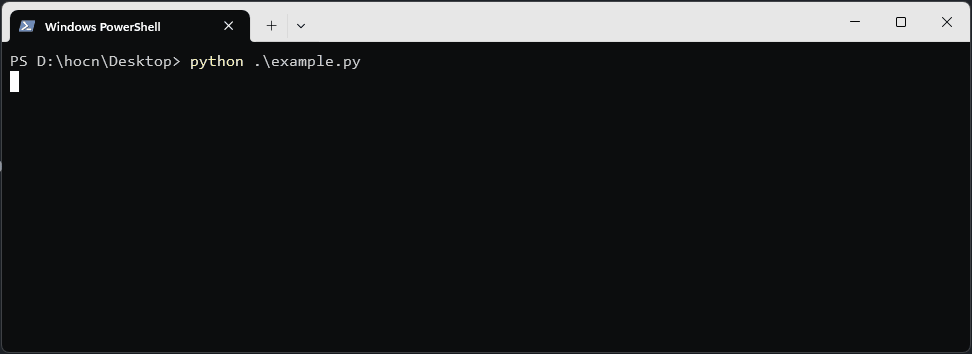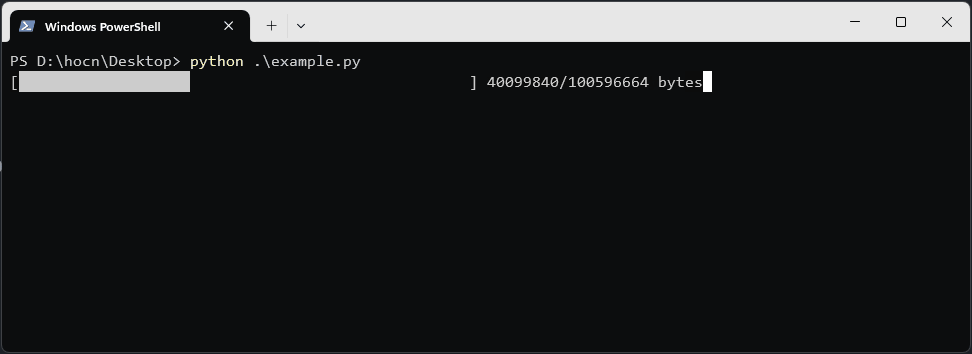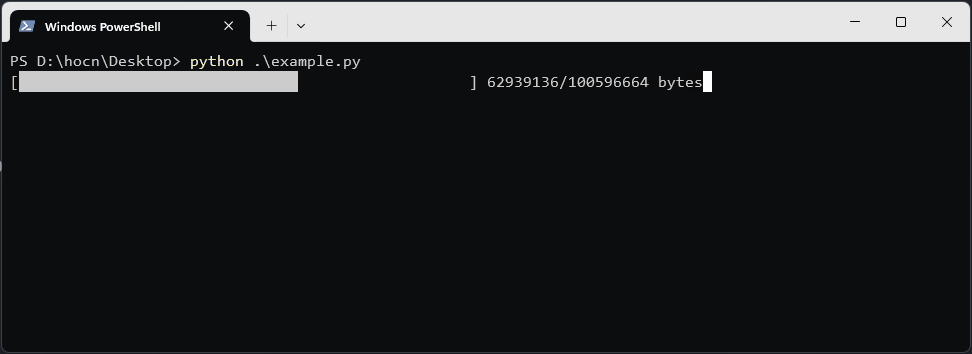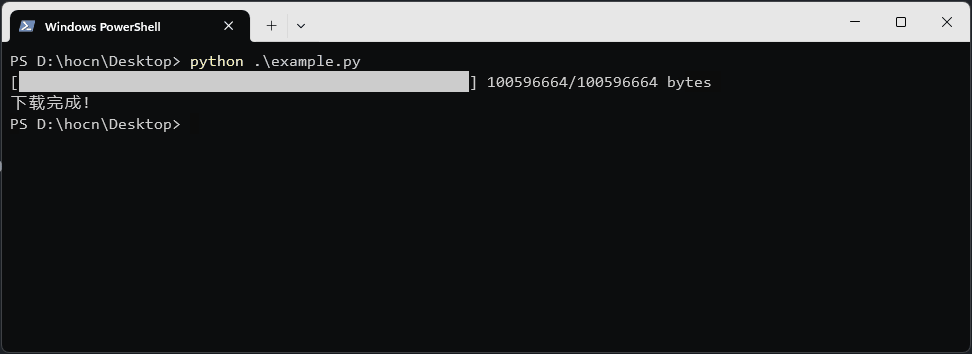
print(f"\r[{'█' * done}{' ' * (50 - done)}] {downloaded_size}/{total_size} bytes", end='')
print("\n下载完成!")
except requests.exceptions.RequestException as e:
print(f"请求错误:{e}")
download_file('http://example.com/largefile.zip','largefile.zip')
核心代码讲解
获取要下载的文件大小
total_size = int(response.headers.get('content-length', 0))
通过HTTP请求响应头中的Content-Length字段可获取文件大小;该字段可能不存在(比如文件是动态生成的);
显示进度
downloaded_size += len(chunk)
if total_size == 0:
done = 0
else:
done = int(50 * downloaded_size / total_size)
print(f"\r[{'█' * done}{' ' * (50 - done)}] {downloaded_size}/{total_size} bytes", end='')
进度条的长度为50个单位;通过计算可得到已下载的单位数量以及剩余数量;